
如何用scikit-learn和pandas在Python中代写拓端tecdat进行iris数据决策树分类及交叉验证?
本文共计3347个文字,预计阅读时间需要14分钟。在本文中,我将利用Python中的决策树(用于分类)进行讲解。重点将放在基础知识和对最终决策树的理解上。首先,进行一些导入操作:pythonfrom __future__ import pr
共收录篇相关文章
本文共计3347个文字,预计阅读时间需要14分钟。在本文中,我将利用Python中的决策树(用于分类)进行讲解。重点将放在基础知识和对最终决策树的理解上。首先,进行一些导入操作:pythonfrom __future__ import pr

本文共计561个文字,预计阅读时间需要3分钟。目录+ 例子+ 数据简单图+ 绘制结果图+ 如何测试+ 数据简单图+ 摘要+ 使用Spearman等级相关性测试两个等级变量或一个等级变量和一个测量变量之间的相关性目录例数据简单图
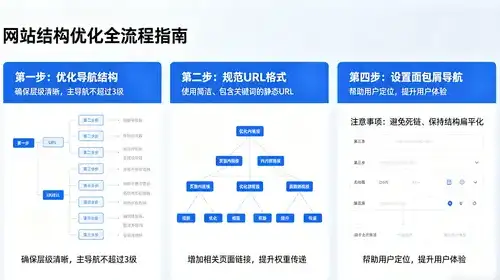
本文共计785个文字,预计阅读时间需要4分钟。拥有一个专门用于预测单变量时间序列的神经网络模型,可以用于预报变量随时间的变化。将神经网络模型拟合到时间序列数据,将时间序列的滞后值作为输入,以此来预测未来的趋势。由于这是一个非线性模型,无法直

本文共计1369个文字,预计阅读时间需要6分钟。在数据密集时代,用户行为数据成为数据分析的关键,深刻影响着人们的生活和学习。同时,对图书馆的发展也产生着影响。在图书馆的议题下,知乎用户问答成为数据基础,为分析提供支持。当前是大数据盛行的时代

本文共计3589个文字,预计阅读时间需要15分钟。前言:本文介绍了R语言中实现分布滞后非线性模型(DLM和DLNM)的建模方法。首先,简要描述了除时间序列数据外的DLM和DLNM的一般化方法,Gasparrini等人在2014年的研究中提供

本文共计230个文字,预计阅读时间需要1分钟。最近,我们利用隐马尔可夫模型(HMM)开发了一种解决方案,并需要解释这个方案。HMM用于构建数据序列模型,无论是基于连续概率分布还是离散概率分布。它涉及状态空间和高度斯混合模型。最近,我们使用隐
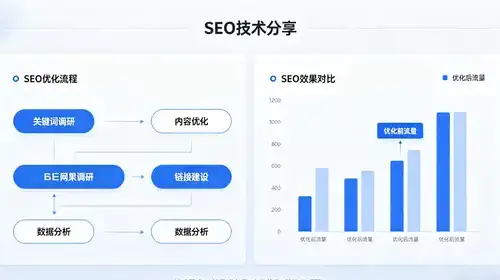
本文共计1442个文字,预计阅读时间需要6分钟。对那些不太熟悉股票概念的人来说,可以简单地说:股票的走势不是由公司业绩主导,而是由整体市场走势主导。这就好比是蝴蝶效应的来源,一个小小的因素都可能影响整个股票的表现。对于那些不熟悉“配对交易”

本文共计1591个文字,预计阅读时间需要7分钟。今年的收益是否真的与典型年份的预期不同?差异是否在现实中与典型年份的预期相符?这些问题都容易回答。我们可以使用平均值相等或方差相等的检验。但下面这个问题呢?今年的收益是否与典型年份的预期不同?