
Spark中,sc.textFiles()与sc.wholeTextFiles()在处理文本文件时,有何本质差异?
本文共计532个文字,预计阅读时间需要3分钟。由于业务需求,需要将大量文件按照目录分类的方式存储在HDFS上。此时,从HDFS上读取文件就需要使用sparkcontext.wholeTextFiles()方法。众所周知,sc.text是由s
共收录篇相关文章
本文共计532个文字,预计阅读时间需要3分钟。由于业务需求,需要将大量文件按照目录分类的方式存储在HDFS上。此时,从HDFS上读取文件就需要使用sparkcontext.wholeTextFiles()方法。众所周知,sc.text是由s
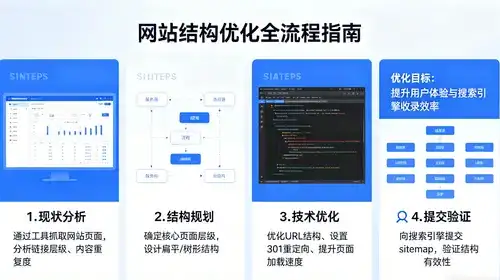
本文共计3018个文字,预计阅读时间需要13分钟。Spark基础:基石RDDSpark的核心是RDD(弹性分布式数据集),一种通用的数据抽象,用于封装一系列元素。RDD支持两种操作:转换(Transformation)和行动(Action)

本文共计2395个文字,预计阅读时间需要10分钟。文章目录 + 读取数据 + 数据源 + 数据格式 + 保存 + JSON + CSV + SequenceFile + 对象文件 + 非文件系统数据源 + Protocol Buffer文章

本文共计901个文字,预计阅读时间需要4分钟。引言:随着数据量的不断增长,大数据技术在过去几年中取得了巨大进步。在这个领域,Hadoop和Spark成为了备受瞩目的框架。本文将探讨它们的发展历程以及在数据处理中的应用。引言:随着数据量的不断
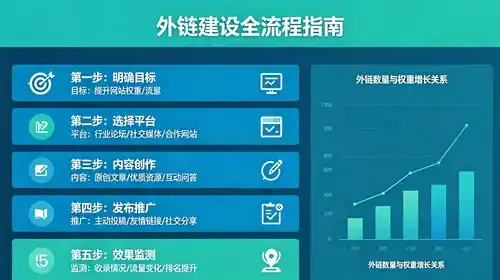
本文共计3787个文字,预计阅读时间需要16分钟。大数据生态圈简介:大数据生态圈可以分为7层,总体上可以归纳为数据采集层、数据计算层和数据应用层。Spark简介:Spark是一种计算引擎,类似于Hadoop架构下的MapReduce,但与M

本文共计384个文字,预计阅读时间需要2分钟。我在考虑将我的一个项目(以及后续的其他项目)从伪原创引擎切换到Spark+View Engine。但今天的研究之后,我遇到了Visual Studio 2010缺少IntelliSense的问题